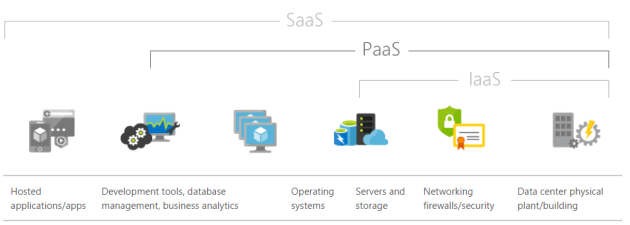
Introdução ao Azure Data Factory
2 de abril de 2018 1 Comentário
Galera,
Estou começando hoje uma série de posts sobre o Azure Data Factory, ferramenta de ETL do MS Azure.
Ele nos permite fazer integração entre várias fontes de dados diferentes que estejam
on-premisses ou na nuvem, estes dados poderão ser transformados de várias maneiras possíveis e depois armazenados em um repositório que servirá de base para relatórios, por exemplo.

Objetivo a ser atingido com o artigo: Apresentar conceitos básicos sobre o ADF e criar uma integração simples entre uma storage account e um Azure Data Lake.
Terminologias
Antes de tudo precisamos entender alguns termos comuns que são utilizados no Data Factory:
- Pipeline: agrupamento lógico de atividades que executam uma determinada atividade. Um Data Factory pode ter N pipelines.
- Atividade: Representa a menor unidade de processamento. Cada um executa um tipo de atividade dentro do pipeline; Podendo se dividir em:
- data movement activities
- data transformation activities
- control activities.
- Dataset: estruturas de armazenamento de dados que servem como input e output para as atividades.
- Linked server: Informações sobre as fontes de dados a serem usadas (connection strings)
- Trigger: Como será disparada a execução do pipeline.
Criando um Data Factory
Para dar inicio na nossa PoC, precisamos criar todos os recursos que a compõe.
O primeiro deles é o Azure Data Factory.
Abra o portal do Azure e crie um novo recurso.

A definição dos parâmetros iniciais é bem auto-explicativa

Criando Storage Account (fonte de dados)
Continuando, vamos criar nossa fonte de dados. É aqui que a atividade de input de dados do pipeline irá buscar os dados para dar inicio ao processo.
Crie uma storage account, e insira um arquivo de texto, como blob, no seguinte formato dentro de um

| nome,idade |
| dhiego,piroto |
| fernanda,tomiko |
| carlos,medeiros |
Criando Azure Data Lake (Destino dos dados)
Agora vamos criar o destino dos nossos dados.
Não se preocupe se você nunca usou o ADL, vamos começar com o básico.

A definição dos parâmetros, assim como os do ADF, é bem auto-explicativa.

Gimme my demo!
Agora que já compreendemos alguns conceitos básicos e fizemos a criação do nosso ambiente, vamos para nossa demo de integração de dados.
Para manter as coisas simples, vamos criar essa primeira integração através do wizard que o Azure portal nos dá. Então acesse o nosso recém criado Azure Data Factory

A configuração via wizard é bem simples e precisamos nos atentar em alguns poucos detalhes:
Nome da task:

Fonte de Dados

onde, em nossa storage account, está o arquivo:

Qual padrão que o arquivo está, como é o delimitador de colunas e como é feita a quebra de linha?

Destino dos dados
Vamos mandar para nosso data lake

Precisamos trocar o tipo de autenticação de “principal” (que demandaria criar um application id no AD do Azure) para OAuth.

Como é o padrão que os dados vão ser exportados para o data lake

Como será o comportamento em caso se falha e qual será o nível de paralelismo

Validemos todos as informações.
Clique ‘Authorize’ para entrar com suas credencias do Azure (OAuth)

Acompanhando o deploy:

No final podemos ver isso nos diretório do nosso ADL e ver se o arquivo está lá

Você pode monitorar a execução de todos os seus pipelines no portal do Azure Data Factory: https://datafactory.azure.com

Você poderá ver
- Um modelo gráfico do seu código que exibe todas as entidades relacionadas ao seu pipeline.
- Um correspondente, em json, ao seu pipeline
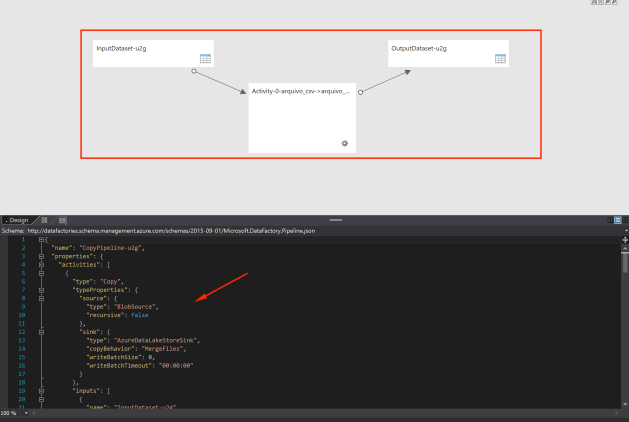
Pessoas, o exemplo de hoje foi bem simples, mas no decorrer da série vamos trabalhar algumas coisas mais complexas como: transformação de dados, agendamento de execuções, importação de pacotes DTS, integração com azure functions e outros.
Referencias
https://docs.microsoft.com/en-us/azure/data-factory/introduction
[]`s
Piroto