Fala Galera,
Continuando falando um pouco sobre as features de segurança do SQL Server, hoje vou abordar o Always Encrypted.
Espero que gostem 🙂
A Microsoft introduziu o Always Encrypted no SQL Server 2016 – Enterprise Edition. Essa feature foi desenhada para proteger dados sensíveis que sejam armazenados na base de dados (Azure ou on-premise) até mesmo do próprio DBA.
É importante ter em mente que o Always Encrypted é uma criptografia Client-side, ou seja, o driver de comunicação da sua aplicação com o SQL Server faz todo o trabalho.
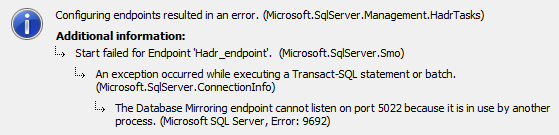
Na imagem 1 temos essa explicação de maneira visual.
- A aplicação dispara uma consulta para o SQL Server pedindo dados, que podem ou não estar criptografados. Caso estejam, o proprio driver (parte vermelha) criptografa as informações antes de enviar para o SQL.
- O SQL Server atende a query e envia as informações solicitadas, tal qual está armazenado no DB.
- O driver (parte vermelha) faz a descriptografia, se for o caso, e apresenta os dados para a aplicação em um texto legível.
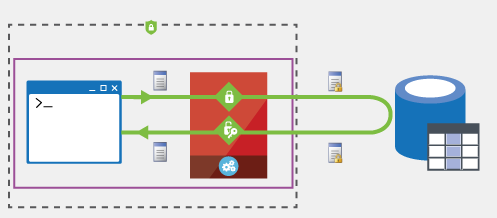
Imagem 1 – Data Encryption
A chave que a aplicação vai usar para criptografar/descriptografar os dados não são armazenadas no SQL Server. Elas podem estar em:
- Windows Certificate Store
- Azure Key Volume
- Hardware security modules
A criptografia é realizada a nível de coluna da tabela (se precisa de algo mais granular, consulte: Cell Level Encryption );
Sua implementação é simples e envolve pouquíssimas alterações na camada de aplicação. (falaremos delas no final do post)
Encryption Type
Quando escolhemos quais colunas devem ser criptografadas, precisamos escolher qual o tipo de criptografia será utilizada. Há duas opções:
- Determinístico: “um algoritmo determinístico é um algoritmo em que, dada uma certa entrada, ela produzirá sempre a mesma saída, com a máquina responsável sempre passando pela mesma seqüência de estados”.
Dito isso, fica fácil entender esse tipo de encriptação. Quando ela é últil? Bem, pense que o SQL Server vai poder usar o valor da sua chave em uma B-Tree. Dependendo do que você precise armazenar, isso vai fazer uma boa diferença na performance das consultas.
- Randômico: Cada hash gerado será único, não importando o valor do dado original.
Keys
Além do tipo de criptografia, também é necessário definir as chaves que serão usadas:
Column Encrypted Key
Usada como base para criptografar uma coluna. Quando olhamos para um exemplo de seu código de criação, notamos a referência para:
- Master Key
- Algoritmo da criptografia
- Valor que é usado para gerar o blob criptografado.
CREATE COLUMN ENCRYPTION KEY [CEK_Auto1]
WITH VALUES
(
COLUMN_MASTER_KEY = [CMK_Auto1], --1
ALGORITHM = 'RSA_OAEP', --2
ENCRYPTED_VALUE = 0x016E000001630075007200720065006E00740075007300650072002F006D007<...> --3
)
Se subirmos mais um nível e analisarmos o código de criação da master key, vamos notar que o local que ela está armazenada é em um endereço fora do SQL Server.
CREATE COLUMN MASTER KEY [CMK_Auto1]
WITH
(
KEY_STORE_PROVIDER_NAME = N'MSSQL_CERTIFICATE_STORE',
KEY_PATH = N'CurrentUser/my/373FA26F3BB2BBDB7181A37EF4FA1B4264239E5D'
)
Se o certificado não está no SQL Server, ele só pode estar em um lugar: na máquina que faz o acesso ao SQL Server.
Lembra-se que eu disse que o Always Encrypted é uma criptografia Client-Side ? Pois é…
Hands On
Para essa demo, vamos criar uma nova tabela e popula-la com alguns dados fictícios.
CREATE DATABASE BLOG_PIROTO
GO
USE BLOG_PIROTO
GO
CREATE TABLE DBO.ALWAYS_ENCRYPTED_DEMO(
ID INT IDENTITY(1,1),
TEXTO1 VARCHAR(10),
TEXTO2 VARCHAR(10)
)
GO
--Vamos fazer um insert com dados fictícios e depois comparar os
--tipos de encriptação usado para cada coluna
DECLARE @I INT = 0
WHILE @I &amp;amp;amp;lt;= 100 BEGIN
DECLARE @TEXTO VARCHAR(10) = REPLICATE('X',RAND()*10)
INSERT INTO DBO.ALWAYS_ENCRYPTED_DEMO (TEXTO1,TEXTO2)
VALUES (@TEXTO,@TEXTO)
SET @I += 1
END
Para deixar o processo de simulação mais simples, vamos seguir usando o Always Encrypted Wizard. Ele pode ser encontrado em:

O primeiro passo é definirmos quais as colunas que queremos que seja criptografas, qual o tipo de criptografia (Determinístico ou randômico) e qual a chave de criptografia; Como ainda não temos uma, o assistente vai cria-la.

Clique em next e defina as opções de armazenamento para sua Master key. Next > Next e Finish.

O que o SQL Server está fazendo agora é criando, armazenando e aplicando as chaves de criptografia na nossa tabela.
Agora, no SSMS, vamos gerar o DDL da nossa tabela e ver quais as alterações

O resultado é:

O tipo do dado continua o mesmo mas a cláusula “Encrypted With” foi adicionada na definição das colunas. Nessa cláusula todas as opções da nossa criptografia são explicitadas.
Chama a atenção é que o collation da coluna também foi alterado para: Latin1_General_BIN2; Isso é uma premissa.
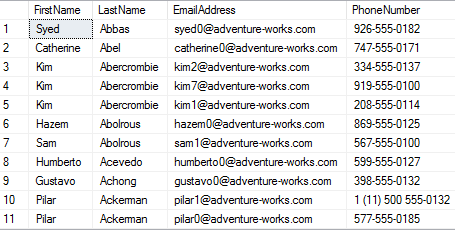
E como estão os dados da tabela?
SELECT * FROM DBO.ALWAYS_ENCRYPTED_DEMO

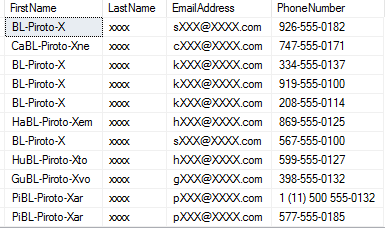
Nada do valor real dos campos. Só temos um hash.
Vamos fazer uma consulta contar quantas ocorrências há de cada uma dos hashs, para entender a diferença entre os tipos de criptografia.
SELECT TEXTO1, COUNT(*) FROM [ALWAYS_ENCRYPTED_DEMO] GROUP BY TEXTO1

Bem, o campo “Texto1” nós configuramos como “Determinístico”. Então, cada cada campo que o valor for, por exemplo, “XXX” o mesmo hash vai ser gerado.
Como ficaram os dados na coluna que os hash foram gerados randomicamente?
SELECT TEXTO2, COUNT(*) FROM [ALWAYS_ENCRYPTED_DEMO] GROUP BY TEXTO2

Ooops! Mesmo a forma randômica sendo mais segura, ela tem uma série de limitações.
Precisamos ter em mente qual o tipo de dados e como ele é consultado na hora de escolher um tipo de criptografia.
Por exemplo, se escolhêssemos a criptografia randômica para um campo que armazene a senha de um usuário, não haveria problema…já se fosse para o campo CEP, poderíamos limitar as consultas que poderíamos fazer.
DMVs – Colunas Criptografadas
Quando for necessário consultar quais colunas da sua base de dados são criptografadas pelo Always Encrypted, basta executar a query abaixo:
SELECT
OBJECT_NAME(OBJECT_ID),
NAME,
COLLATION_NAME,
ENCRYPTION_TYPE_DESC,
ENCRYPTION_ALGORITHM_NAME
FROM SYS.COLUMNS
WHERE ENCRYPTION_TYPE_DESC IS NOT NULL
Certificado
O tema “certificado” é bem extenso e, aborda-lo a fundo, não faz parte do escopo deste artigo.
O que você precisa saber é:
- O Certificado está na minha máquina?
Para isso o Powershell vai te dar uma mão:
$chave="373FA26F3BB2BBDB7181A37EF4FA1B4264239E5D"
Get-ChildItem -Recurse Cert:| where Thumbprint -eq $chave
O parâmetro “$chave” precisa ser preenchido com o mesmo valor do campo KEY_PATH da sua Master Key.

https://blogs.msdn.microsoft.com/sqlsecurity/2016/07/05/developing-databases-using-always-encrypted-with-sql-server-data-tools/
Alterar minha aplicação?
No início deste post eu havia dito que a implementação do Always Encrypted era simples e necessitava “pouquíssimas alterações na camada da aplicação”.
Pois bem, a alteração é simples e rápida.
Se você estiver usando .NET, basta abrir seu web.config e adicionar a sua string de conexão o parâmetro “column encrypton setting=enable” e voilà.
E o SSMS?
Tudo muito bacana, tudo muito bom mas, e se você quiser ver os dados sem criptografia direto pelo SQL Server Management Studio?
Bom, aí você pode consultar esse post aqui (em construção)
Por hoje é isso 🙂
[]’s
Piroto